
Sometimes, retrospectively looking back on how software development and IT operations have evolved over the years is important. Over the last several years, we have seen the rise to prominence of two key methodologies: Agile and DevOps.
Nowadays, these terms form part of the everyday vernacular for organisations leveraging complex software development. While these terms are often mentioned in the same breath, it’s important to isolate some of their distinct characteristics and applications, as those new to this terrain may need clarity.
As a leading Agile and DevOps recruitment agency for technical contractors, we at ClearHub felt it prudent to break down the key differences and similarities between Agile and DevOps, and explain why understanding both is critical for businesses today.
Understanding Agile
Agile emerged in the early 2000s as a response to traditional, rigid development methodologies.
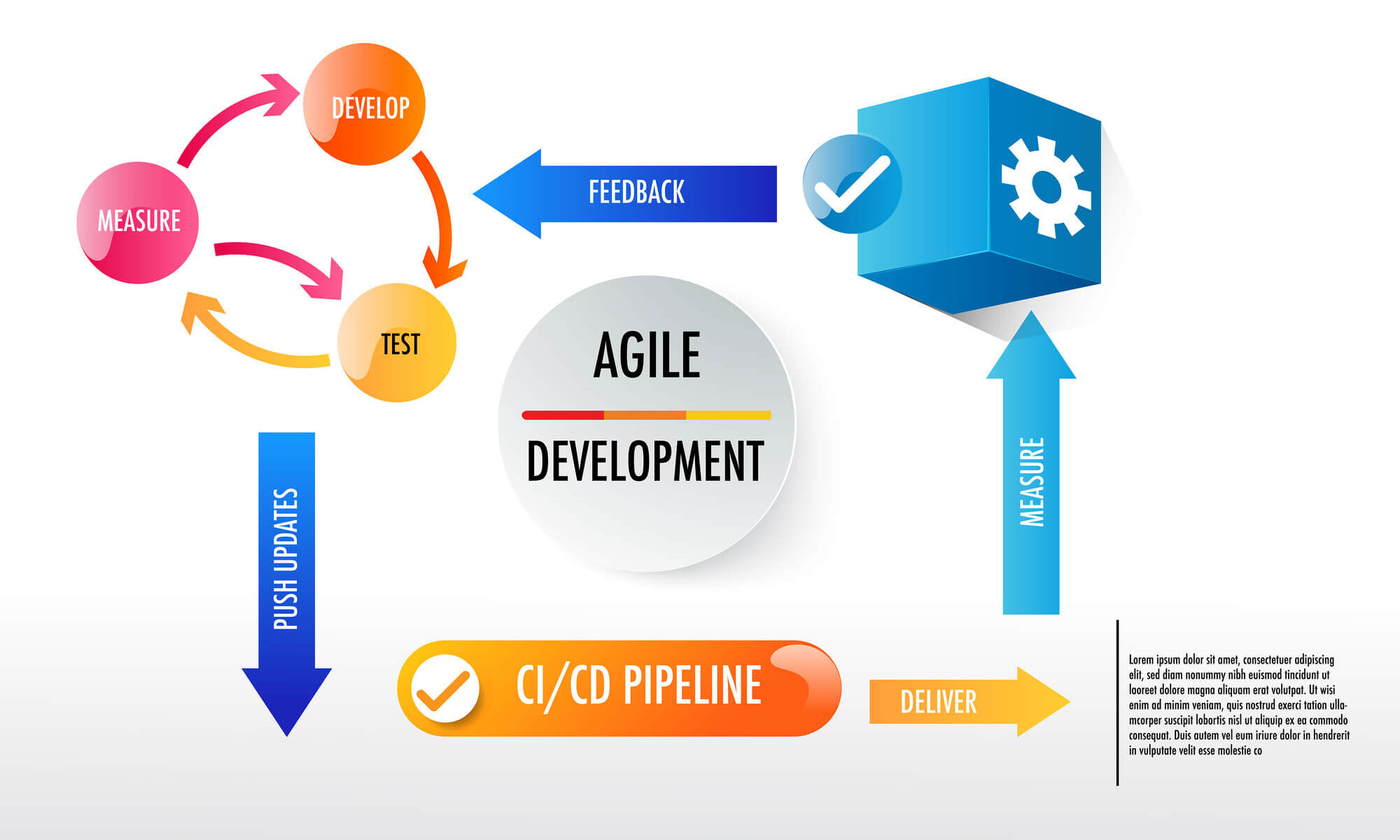
At its core, Agile is an iterative approach to project management and software development that emphasises:
- Collaboration and customer feedback
- Rapid, incremental releases
- Flexibility and adaptability to change
In an agile approach, some planning and design tasks are done upfront, but the development is executed incrementally in close collaboration with key stakeholders. Changes are incorporated continuously and usable versions of products are often released quickly compared to those developed through tried-and-tested waterfall methodologies.
The Agile Manifesto, which outlines the methodology’s principles, prioritises four key values:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
Agile methodologies, such as Scrum and Kanban, have drastically influenced how modern software development teams work, allowing them to deliver value to customers more quickly and efficiently.
Understanding DevOps
While Agile focused primarily on improving the development process, it became apparent that there were missing pieces of the puzzle on the operations side.
Enter DevOps, a methodology that aims to bridge the gap between development and operations teams. It is a methodology that enables teams to build, test, and release software much more reliably and quickly by incorporating agile principles.
DevOps is an approach that:
- Aligns development and operations teams
- Emphasises automation and continuous delivery
- Focuses on the entire software lifecycle, from development to deployment and maintenance
DevOps engineers attempt to break down silos between teams, fostering a culture of collaboration and shared responsibility. This approach leads to faster deployment times, improved quality, and more reliable software products.
The DevOps “Three Ways” are as follows:
- Systems thinking – Understanding that software applications are complex systems
- Amplifying feedback loops – Improve bidirectional communication between teammates
- Cultural change – Culture of continuous experimentation and learning
Key Differences Between Agile and DevOps
While Agile and DevOps share some common ground, there are several key differences:
- Scope: Agile primarily focuses on the development process, while DevOps encompasses the entire software lifecycle, including operations.
- Team composition: Agile typically involves developers and product managers, whereas DevOps brings operations teams into the fold.
- Delivery focus: Agile emphasises iterative development and small batches, while DevOps places a strong emphasis on continuous integration and delivery through CI/CD pipelines.
- Automation: While both methodologies value automation, DevOps places a much heavier emphasis on automating the entire pipeline, from testing to deployment.
- Feedback loops: Agile focuses on customer feedback for product improvements, while DevOps extends this to include operational feedback for system optimisation.
Similarities Between Agile and DevOps
Despite their differences, Agile and DevOps share several common principles:
- Both methodologies stress the importance of fostering teamwork and breaking down operational silos
- Agile and DevOps both advocate for the ongoing refinement of processes and products.
- Both prioritise delivering value to the end-user quickly and efficiently.
- Agile and DevOps both emphasise the ability to adapt to changing requirements and circumstances.
In many ways, DevOps can be seen as an evolution of Agile principles, extending them beyond the development team to encompass the entire software delivery pipeline.
Why Understanding Both Matters for Your Business
In such a fast-paced software development market, businesses need to be able to deliver high-quality applications and products quickly and reliably. Understanding and implementing both Agile and DevOps methodologies can provide several benefits:
- Faster time-to-market through streamlined and collaborative processes
- Improved software quality thanks to continuous testing and feedback loops
- Increased efficiency through process automation and productivity among teams
- Quicker responses to market changes and customer needs
- Faster delivery of products leads to greater customer satisfaction and a better competitive edge for vendors
The Importance of Skilled Agile and DevOps Contractors
As businesses strive to implement Agile and DevOps practices, the need for skilled professionals who understand these methodologies becomes crucial. This is where ClearHub comes in. We specialise in connecting businesses with experienced DevOps and Agile contractors who have expertise in:
- Agile methodologies (Scrum, Kanban, etc.)
- DevOps practices and tools
- Cloud technologies and migration
- Atlassian products (Jira, Confluence, Bitbucket)
- CI/CD pipelines
Whether you’re looking to implement Agile practices, build a DevOps culture, or need expertise in specific tools and technologies, our network of skilled technical contractors can help your business thrive in the modern software development landscape.
Hire Agile or DevOps Contractors Today
As you navigate the complexities of modern software development, remember that having the right talent is key to success. ClearHub is here to help you find the right skilled Agile and DevOps contractors for hire, who can take your projects to the next level. Contact us today to learn how we can support your business in implementing these crucial methodologies and remaining one step ahead of the competition.






